









DiscoverText
DiscoverText es un software basado en la nube con soluciones colaborativas de análisis de texto.
Análisis de texto colaborativo para aprendizaje humano y automático.
Ofrecemos docenas de funciones multilingües, minería de texto, ciencia de datos, anotación humana y aprendizaje automático. DiscoverText ofrece una variedad de herramientas de software basadas en la nube, desde simples hasta avanzadas, lo que permite a los usuarios evaluar de forma rápida y precisa grandes cantidades de datos de texto. Nuestros clientes califican el texto libre no estructurado común en la investigación de mercado, así como los metadatos asociados, que también se encuentran en plataformas de comentarios de clientes, CRM, chats, correo electrónico, recursos humanos a gran escala u otras respuestas abiertas en encuestas, comentarios públicos para agencias gubernamentales, Twitter, RSS feeds y otras formas de datos de texto.
Proveedor: Texifter LLC
SOLICITE UNA COTIZACIÓN
DiscoverText es una pequeña empresa aprobada por GSA hasta 2024 para 54154S y 54151ECOM. Lea más de 100 reseñas autenticadas de Capterra para descubrir por qué ocupamos el primer lugar en análisis predictivo, texto, metadatos y soporte de análisis de redes sociales, en el que confían cientos de grupos de investigación académica. Los académicos tienen acceso y formación gratuitos hasta finales de 2021.
- Recopilar, limpiar y analizar datos de texto.
Los datos de texto no estructurados son confusos.
Los científicos de datos que trabajan con análisis de texto saben que la limpieza de datos puede llevar mucho tiempo. Los usuarios de DiscoverText crean clasificadores de máquina personalizados reutilizables o "tamices" para encontrar los elementos más (o menos) relevantes antes de usar otros clasificadores para clasificar los elementos por tema, sentimiento y otras categorías. DiscoverText combina métodos de ciencia de datos híbridos (medición, adjudicación, iteración, replicación) junto con herramientas de análisis de texto de eDiscovery establecidas para acortar un proceso que solía llevar semanas o meses cuando las palabras se ordenaban en hojas de cálculo. Nuestros tamices de aprendizaje automático se crean en horas o solo minutos mediante crowdsourcing. Ofrecemos una API y apoyamos integraciones técnicas con Twitter y SurveyMonkey. Los académicos confían en DiscoverText para ayudarlos a realizar una investigación científica mejor y más transparente, lo que da como resultado publicaciones académicas. Los equipos legales utilizan nuestra función de edición de documentos para eliminar nombres, metadatos, direcciones de correo electrónico y otra información confidencial para producir colecciones de PDF con sello Bates indexadas en hojas de cálculo.
- Los seres humanos y las máquinas clasifican el texto.
Apunte y haga clic en un software que cualquiera puede dominar.
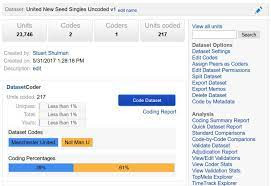
Los seres humanos son buenos en algunas cosas y las computadoras en otras. Un intercambio constante entre humanos y máquinas aumenta su capacidad para aprender. Nuestro software de análisis de texto y métodos de ciencia de datos surgen de una década de investigación financiada por la National Science Foundation sobre medidas que aceleran el aprendizaje automático. La clasificación de los textos es un problema antiguo y difícil, según nada menos que Platón. Nuestro método de adjudicación único y probado crea conjuntos de capacitación estándar de oro para el aprendizaje automático, clasificando a las personas que toman notas a lo largo del tiempo. Un enfoque CoderRank patentado es fundamental para garantizar resultados precisos y confiables cuando finalmente se evalúa el trabajo de humanos o máquinas.
- Herramientas de eDiscovery que funcionan.
Técnicas avanzadas de investigación y muestreo.
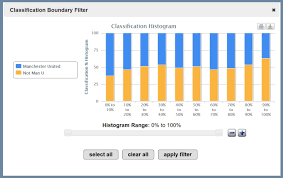
La deduplicación y la agrupación en clústeres automatizada de casi duplicados brindan a los usuarios una idea de alto nivel del panorama de los datos. Con los datos de Twitter, estas agrupaciones son una hoja de ruta para la huella digital de los Tweets virales. Con datos de comentarios públicos, estas agrupaciones son cartas estándar y formularios modificados. En encuestas a gran escala, a menudo se realizan duplicados y casi duplicados, pero las opiniones se expresan de forma independiente entre los clientes o empleados. Nuestros histogramas de clasificadores de máquinas interactivos permiten a los equipos de ciencia de datos identificar los elementos de una colección que agregan el mayor valor cuando son codificados por humanos. Estas herramientas de análisis de texto permiten un muestreo intencionado que acelera aún más el proceso de entrenamiento de clasificadores de máquinas.
¡Gracias! ¡Nos pondremos en contacto con usted pronto!
Baixe o Guia Software.com.br 2024








